Introducing The Swahili Thinking Dataset
The first open-source Swahili chain-of-thought reasoning dataset

Introduction
Today, we are excited to release the Swahili Thinking Dataset, the first open-source dataset for chain-of-thought reasoning in Swahili. This dataset contains 166 high-quality examples of conversational AI responses where models explicitly demonstrate their reasoning process before generating final answers.
While chain-of-thought reasoning datasets exist for major languages like English, French, and Spanish, there are no publicly accessible high-quality chain-of-thought reasoning datasets for African languages. The Swahili Thinking Dataset addresses this gap, enabling researchers and developers to build more capable Swahili language models that can think before they respond.
Dataset Overview
The dataset was created by professionally translating 200 English examples from the HuggingFaceH4/Multilingual-Thinking dataset using GPT-5 Pro, resulting in 166 successful translations. Each example demonstrates explicit reasoning in Swahili across diverse conversational scenarios.
Dataset Structure
Each example contains six fields following the Harmony response format:
- reasoning_language: Always "Swahili"
- developer: System prompt in Swahili defining the assistant's role
- user: User query in Swahili
- analysis: Chain-of-thought reasoning process in Swahili
- final: Final response to user in Swahili
- messages: Formatted conversation with thinking field
Example Conversations
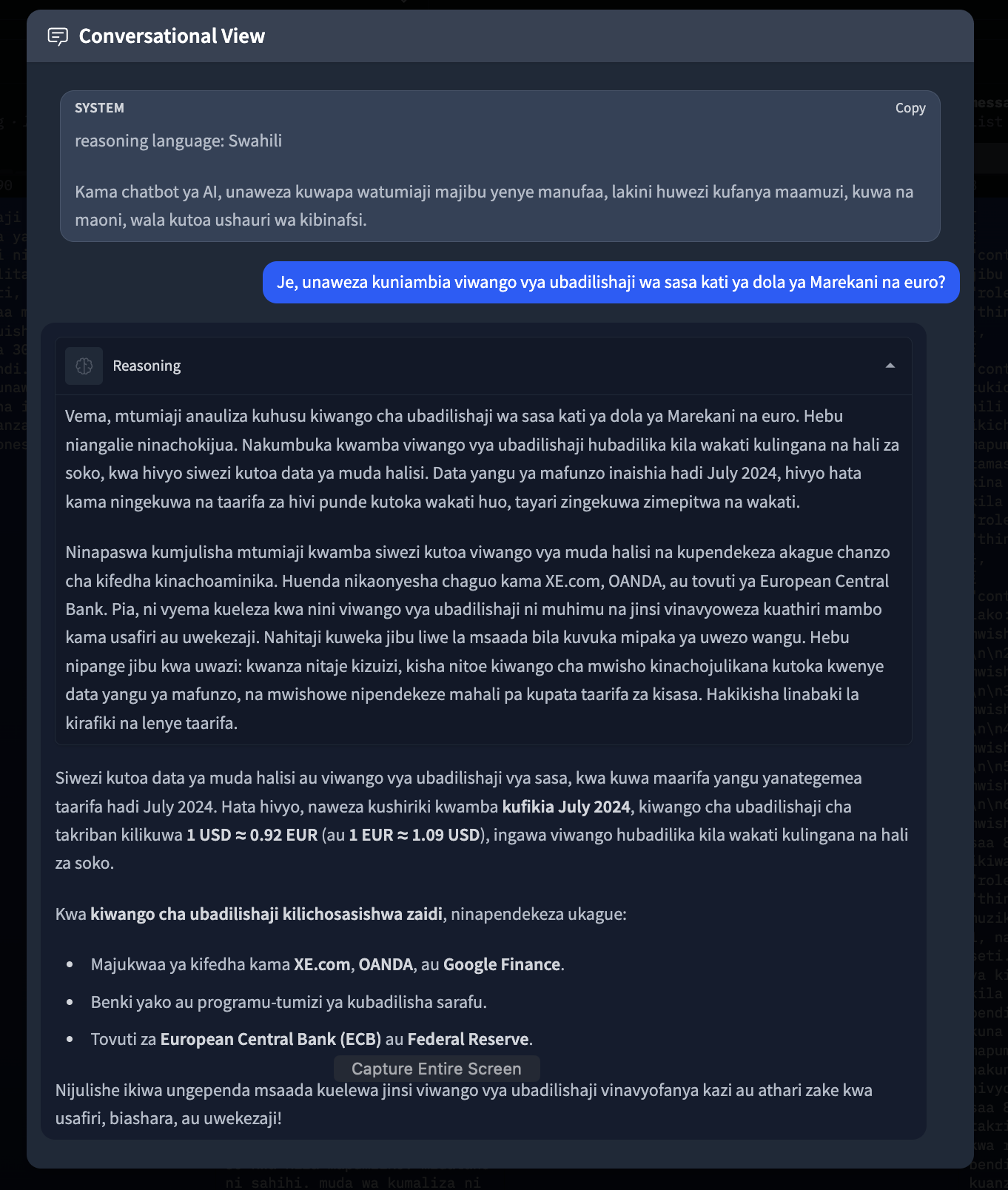
Example showing multi-step reasoning about currency exchange rates, demonstrating the model's ability to break down complex queries into logical steps.
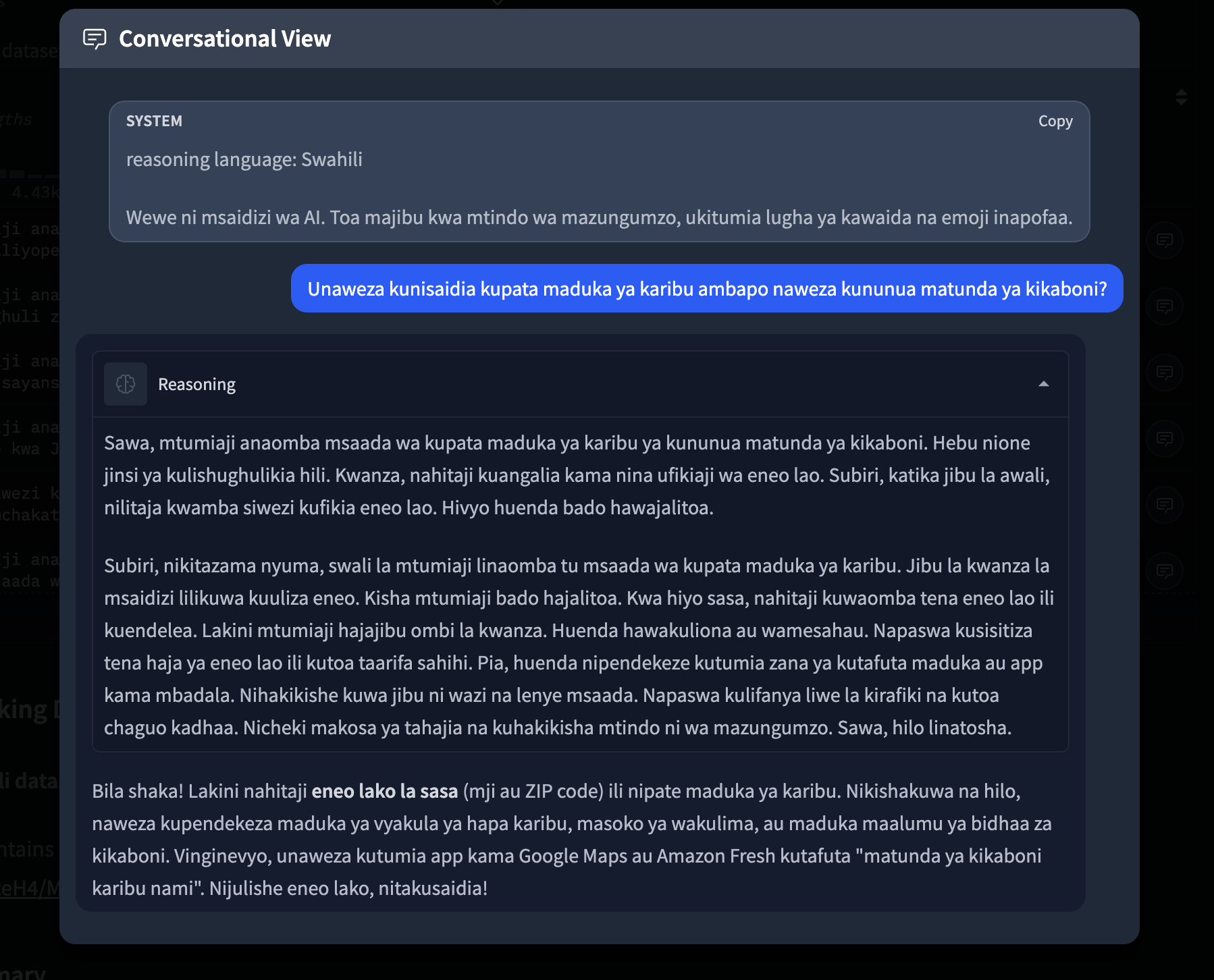
The model reasons through how to help users find nearby grocery stores, considering multiple approaches and regional context.

Detailed reasoning process for recommending historical fiction books, showing consideration of multiple criteria and diverse options.
Loading the Dataset
You can load the dataset directly from HuggingFace:
from datasets import load_dataset
dataset = load_dataset("Nadhari/Swahili-Thinking", split="train")
# Access first example
example = dataset[0]
print(example['user']) # User query in Swahili
print(example['analysis']) # Chain-of-thought reasoning
print(example['final']) # Final response
Use Cases
This dataset enables several important applications:
- Fine-tuning Language Models: Train Swahili models to perform explicit reasoning before generating responses, improving accuracy and transparency
- Research: Study multilingual reasoning patterns and cross-lingual transfer learning
- Low-Resource Language AI: Advance capabilities for African languages in modern AI systems
Dataset Statistics
- Total examples: 166
- Source: HuggingFaceH4/Multilingual-Thinking (English subset)
- Translation model: GPT-5 Pro (gpt-5-pro-2025-10-06)
- Average reasoning length: ~2,000 characters
- Average response length: ~2,000 characters
Future Plans
This release is just the beginning. We plan to:
- Expand the dataset with additional examples across more domains
- Include more complex reasoning tasks (mathematical, scientific, coding)
- Create similar datasets for other African languages
- Develop benchmark tasks for evaluating Swahili reasoning capabilities
Community Contributions
We welcome contributions from the community. If you would like to help expand this dataset or have suggestions for improvement, please:
- Open an issue or discussion on our HuggingFace repository
- Submit additional examples following the dataset format
- Share your fine-tuned models using this dataset
- Report any data quality issues
Citation
If you use this dataset in your research, please cite:
@misc{swahili-thinking-dataset-2025,
title={Swahili Thinking Dataset},
author={Nadhari AI},
year={2025},
publisher={HuggingFace},
url={https://huggingface.co/datasets/Nadhari/Swahili-Thinking}
}
Acknowledgments
This work builds upon the excellent Multilingual-Thinking dataset by HuggingFace H4. We are grateful for their contribution to the open-source AI community.
Seti ya Data ya Mantiki za Kiswahili
Dataset ya kwanza ya wazi ya ufikiri wa mnyororo wa mawazo katika Kiswahili
Utangulizi
Leo, tunafurahi kutambulisha Swahili Thinking Dataset, dataset ya kwanza ya wazi (open-source) kwa ufikiri wa mnyororo wa mawazo katika Kiswahili. Dataset hii ina mifano 166 ya ubora wa juu ya majibu ya AI ya mazungumzo ambapo modeli huonyesha wazi mchakato wao wa kufikiri kabla ya kutoa majibu ya mwisho.
Ingawa datasets za ufikiri wa mnyororo wa mawazo zipo kwa lugha kuu kama Kiingereza, Kifaransa na Kihispania, hakuna datasets za ubora wa juu za aina hii zinazopatikana hadharani kwa lugha za Afrika. Swahili Thinking Dataset inashughulikia pengo hili, ikiwezesha watafiti na wasanidi programu kujenga modeli za Kiswahili zenye uwezo zaidi zinazoweza kufikiri kabla ya kujibu.
Muhtasari wa Dataset
Dataset hii iliundwa kwa kutafsiri kitaalamu mifano 200 ya Kiingereza kutoka kwa dataset ya HuggingFaceH4/Multilingual-Thinking kwa kutumia GPT-5 Pro, na kuzaa jumla ya tafsiri 166 zilizofaulu. Kila mfano unaonyesha ufikiri wa wazi kwa Kiswahili katika mazingira mbalimbali ya mazungumzo.
Muundo wa Dataset
Kila mfano una sehemu sita zinazofuata muundo wa majibu wa Harmony:
- reasoning_language: Daima "Swahili"
- developer: Maelekezo ya mfumo kwa Kiswahili yanayoeleza jukumu la msaidizi
- user: Swali au ombi la mtumiaji kwa Kiswahili
- analysis: Mchakato wa ufikiri wa mnyororo wa mawazo kwa Kiswahili
- final: Jibu la mwisho kwa mtumiaji kwa Kiswahili
- messages: Mazungumzo yaliyopangwa pamoja na sehemu ya ufikiri
Mifano ya Mazungumzo
Mfano unaonyesha ufikiri wa hatua nyingi kuhusu viwango vya ubadilishaji wa sarafu, ukionyesha uwezo wa modeli kujibu maswali magumu katika hatua za kimantiki.
Modeli inafikiri hatua kwa hatua jinsi ya kuwasaidia watumiaji kupata maduka ya vyakula yaliyo karibu nao, ikizingatia mbinu tofauti na muktadha wa kikanda.
Mchakato wa kina wa ufikiri wa kupendekeza vitabu vya hadithi za kihistoria, ukionyesha kuzingatia vigezo vingi na chaguo mbalimbali.
Kupakia Dataset
Unaweza kupakua dataset hii moja kwa moja kutoka HuggingFace:
from datasets import load_dataset
dataset = load_dataset("Nadhari/Swahili-Thinking", split="train")
# Fikia mfano wa kwanza
example = dataset[0]
print(example['user']) # Swali la mtumiaji kwa Kiswahili
print(example['analysis']) # Ufikiri wa mnyororo wa mawazo
print(example['final']) # Jibu la mwisho
Matumizi
Dataset hii inafungua matumizi muhimu kadhaa:
- Kuboresha modeli za lugha: Kufundisha modeli za Kiswahili kufanya ufikiri wa wazi kabla ya kutoa majibu, na hivyo kuboresha usahihi na uwazi
- Utafiti: Kuchunguza mifumo ya ufikiri wa lugha nyingi na ujifunzaji wa uhamisho wa lugha (cross-lingual transfer learning)
- AI kwa lugha za rasilimali chache: Kuendeleza uwezo wa lugha za Afrika katika mifumo ya kisasa ya AI
Takwimu za Dataset
- Jumla ya mifano: 166
- Chanzo: HuggingFaceH4/Multilingual-Thinking (sehemu ya Kiingereza)
- Modeli ya tafsiri: GPT-5 Pro (gpt-5-pro-2025-10-06)
- Wastani wa urefu wa ufikiri: ~herufi 2,000 kwa kila mfano
- Wastani wa urefu wa jibu: ~herufi 2,000 kwa kila mfano
Mipango ya Baadaye
Toleo hili ni mwanzo tu. Tunapanga:
- Kupanua dataset kwa kuongeza mifano zaidi katika nyanja mbalimbali
- Kujumuisha kazi changamano zaidi za ufikiri (hisabati, sayansi, uandishi wa msimbo wa kompyuta — coding)
- Kuunda datasets zinazofanana kwa lugha nyingine za Afrika
- Kuendeleza vipimo sanifu vya kutathmini uwezo wa ufikiri wa Kiswahili
Michango ya Jamii
Tunakaribisha michango kutoka kwa jamii. Ikiwa ungependa kusaidia kupanua dataset hii au una mapendekezo ya uboreshaji, tafadhali:
- Fungua suala (issue) au mjadala kwenye hazina yetu ya HuggingFace
- Wasilisha mifano ya ziada inayofuata muundo wa dataset
- Shiriki modeli zako zilizoboreshwa kwa kutumia dataset hii
- Ripoti changamoto zozote za ubora wa data
Nukuu
Iwapo utatumia dataset hii katika utafiti wako, tafadhali taja nukuu ifuatayo:
@misc{swahili-thinking-dataset-2025,
title={Swahili Thinking Dataset},
author={Nadhari AI},
year={2025},
publisher={HuggingFace},
url={https://huggingface.co/datasets/Nadhari/Swahili-Thinking}
}
Shukrani
Kazi hii imejengwa juu ya dataset bora ya Multilingual-Thinking kutoka HuggingFace H4. Tunawashukuru kwa mchango wao mkubwa kwa jamii ya AI ya chanzo huria.