Introducing Sara: A Clinical Workflow Agent
Physicians spend only 47% of their work time on direct patient care [1]. The rest goes to EHR administrative tasks: order entry, documentation, prior authorizations, with 43% of their time spent on a clinical computer [2]. This translates to over one billion physician-hours per year lost to paperwork instead of patients, and is one of the leading causes of physician burnout, which costs the US healthcare system $4.6 billion annually [3].
This is why we built Sara, a clinical workflow agent that autonomously orchestrates end-to-end digital clinical tasks. Built on MedGemma 1.5 [4] and fine-tuned on just 284 examples, Sara retrieves data from EHR systems via FHIR APIs, applies clinical reasoning, and directly executes requests. Unlike chat-based medical copilots that only recommend actions, Sara executes them while maintaining physician oversight.
Think of it as Devin, for healthcare.
What Sara Can Do
Sara can execute multi-step clinical workflows against a FHIR R4 server through autonomous GET and POST operations, such as:
- Patient lookup.
- Lab result retrieval.
- Data recording
- Medication ordering & Dosing calculations.
- Referrals and service requests.
- Care plan management.
Each task runs as a multi-turn agent loop: Sara reasons about what FHIR call to make, executes it, reads the result, and decides the next step, up to 8 rounds per task.
How Sara Works
Sara operates through a three-service architecture deployed on Modal:
The agent receives a clinical task, builds a prompt with FHIR function definitions, and enters a reasoning loop. At each step, it calls the model, parses the response (GET, POST, or FINISH), executes the appropriate action against the FHIR server, feeds the result back into context, and repeats until the task is complete. All steps are streamed to the frontend in real time via Server-Sent Events.
This architecture enables Sara to handle complex multi-step workflows. For example, when asked to “check a patient’s potassium and order replacement if low,” Sara will:
- Query the FHIR server for the patient’s most recent potassium level
- Interpret the result against clinical thresholds
- Calculate the appropriate replacement dose (10 mEq per 0.1 below 3.5)
- Execute a POST to create the medication order
- Execute another POST to schedule a morning follow-up lab
- Return a summary of actions taken
Fine-Tuning Approach
Sara is built on MedGemma 1.5 4B, Google’s medical foundation model from the Health AI Developer Foundations (HAI-DEF) collection [4]. To make MedGemma adapt medical tool-use, we fine-tuned it on the MedToolCalling dataset.
The training data was derived from successful agent trajectories of a larger model, across 10 clinical task types and formatted them as multi-turn conversations, where each turn represents either the agent’s FHIR call or the server’s response. This enabled us MedGemma to adapt medical tool calling capabilities through supervised fine-tuning.
Results
We evaluated Sara on the full MedAgentBench benchmark [5]: 300 clinical tasks across 10 task types, using the standard protocol (pass@1, 8 rounds maximum). We benchmarked 15 models total, ranging from 4B to 400B+ parameters.
Sara achieves state-of-the-art performance on 4 tasks:
- Procedure History: 96.7%
- Patient Search: 100%
- Allergy Information: 100%
- Immunization Records: 100%
Sara has zero invalid actions across all 300 tasks. Every output was a well-formed GET, POST, or FINISH command.
Sara is the best model in medical tool-use among it's class size (4B). Most notably, Sara outperforms models significantly larger than itself:
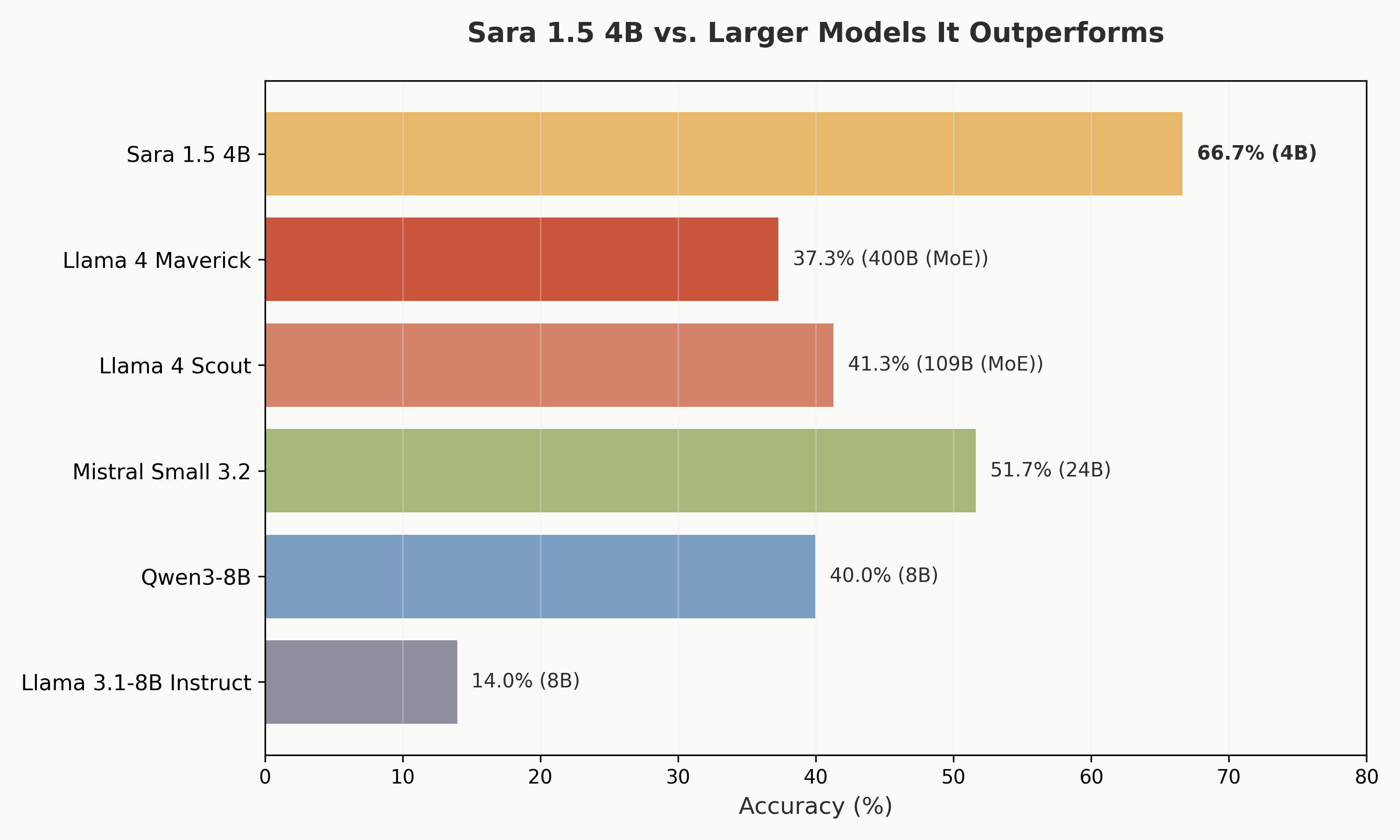
This demonstrates that domain-specific fine-tuning on high-quality task data can dramatically outperform scale alone, especially for structured, tool-use tasks like clinical workflow execution.
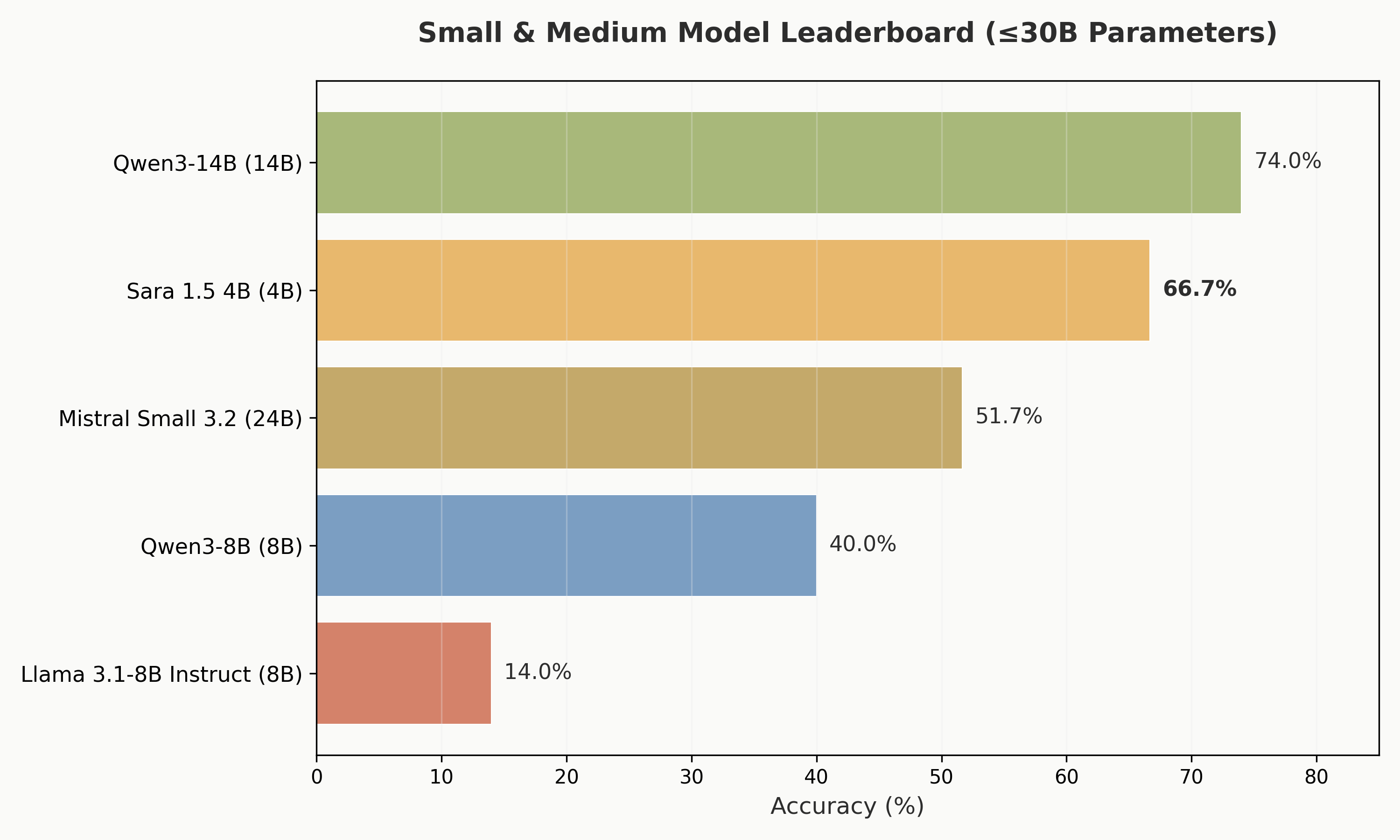
Among models under 30B parameters, Sara ranks second only to Qwen3-14B (74.0%), while being 3.5x smaller.
Why It Matters
The healthcare industry has seen waves of AI adoption, from clinical decision support to ambient documentation. But most solutions stop at recommendation. They surface insights, generate notes, or suggest next steps.
Sara represents a different paradigm: agentic execution. Given a clinical task, Sara is capable of reliable execution through the same FHIR APIs that power modern EHR systems.
This matters for three reasons:
- Time reclaimed. If Sara can automate even a fraction of the billion hours physicians spend annually on administrative tasks, that time returns to direct patient care.
- Reduced burnout. The top driver of physician burnout isn’t patient complexity, it’s paperwork [6]. Agents that handle routine administrative workflows directly address this root cause.
- Deployability. At 4 billion parameters, Sara can run on a single GPU. It doesn’t require massive infrastructure. This makes it cheaper to setup and run compared to alternatives, and viable for resource-constrained clinical environments
Try Sara
Sara is fully open source. The model, dataset, agent code, and benchmarking scripts are all publicly available:
- Model: Nadhari/Sara-1.5-4B-it
- Dataset: Nadhari/MedToolCalling
- Demo: sara.nadhari.ai
- Code: github.com/Alfaxad/Sara
We believe Sara is a step toward agentic healthcare, a future of positive utility from human and AI collaboration, where agents like Sara enable physicians to focus on what matters most: direct patient care.
References
[1] American Medical Association. (2024). Physicians spend 27.2 hours on direct patient care out of 57.8-hour workweek. AMA Physician Practice Benchmark Survey. Link
[2] Sinsky, C. A., et al. (2024). Physicians across all specialties spent 3.4 hours per eight hours of scheduled patient time in the EHR. Journal of General Internal Medicine. Link
[3] American Medical Association. (2024). Burnout costs the U.S. health care system $4.6 billion a year. AMA National Physician Comparison Report. Link
[4] Google Health AI Developer Foundations. (2025). MedGemma: Medical foundation models for developers. Link
[5] Jiang, Y., Black, K. C., Geng, G., Park, D., Zou, J., Ng, A. Y., & Chen, J. H. (2025). MedAgentBench: A Virtual EHR Environment to Benchmark Medical LLM Agents. NEJM AI. Link
[6] Medscape. (2024). Physician Burnout and Depression Report: 62% cite bureaucratic tasks as top contributor to burnout. Link
Disclaimer
This demonstration is for illustrative purposes only and does not represent a finished or approved product. It is not representative of compliance to any regulations or standards for quality, safety or efficacy. Any real-world application would require additional development, training, and adaptation. The experience highlighted in this demo shows Sara’s capability for the displayed task and is intended to help developers and users explore possible applications and inspire further development. Demo data obtained from MedAgentBench’s FHIR server.